


8.6 Abfragen über mehrere Tabellen
Es folgt ein Beispiel mit einer Datenbank, die mehrere Tabellen beinhaltet (Projekt DBMehrereTabellen). Es werden einige Besonderheiten erläutert, die sich bei Abfragen über mehrere Tabellen ergeben. Das Beispiel basiert auf der Übung Projektverwaltung, siehe Abschnitt 8.1.4, bzw. der zugehörigen Lösung. Das Datenbankmodell sehen Sie in Abbildung 8.34.
Zur Erläuterung des Datenbankmodells:
- Kunden werden mit Name und Ort angegeben, Primärschlüssel: Kunden-ID.
- Projekte werden mit Bezeichnung angegeben. Jedes Projekt ist einem Kunden zugeordnet. Primärschlüssel ist die Projekt-ID.
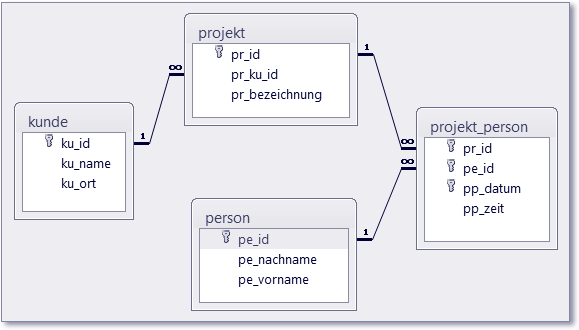
Abbildung 8.34 Datenbankmodell zu »Projektverwaltung«
- Personen werden mit Nach- und Vorname angegeben. Primärschlüssel ist die Personen-ID.
- Die Arbeitszeiten der Personen an den Projekten werden mit Datum und Zeit in Stunden angegeben. Primärschlüssel ist die Kombination aus Projekt-ID, Personen-ID und Datum.
Zum besseren Verständnis der Abfrage-Ergebnisse folgen die Inhalte der Tabellen in den Abbildungen 8.35 bis 8.38.
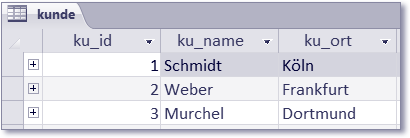
Abbildung 8.35 Inhalt der Tabelle »kunde«
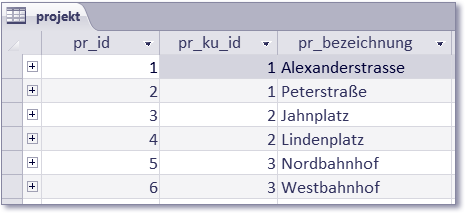
Abbildung 8.36 Inhalt der Tabelle »projekt«
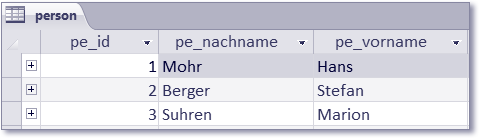
Abbildung 8.37 Inhalt der Tabelle »person«
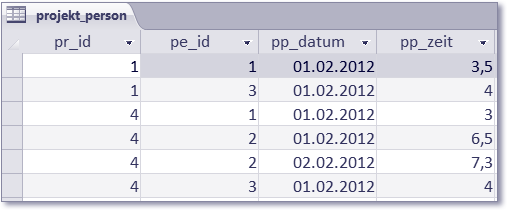
Abbildung 8.38 Inhalt der Tabelle »projekt_person«
Zunächst die Abfrage Alle Personen – das Ergebnis sehen Sie in Abbildung 8.39.
- Es wird für jede Person ein Datensatz ausgegeben.
- Personen werden mit Nachname und Vorname, auch danach sortiert, ausgegeben.
select * from person order by pe_nachname, pe_vorname

Abbildung 8.39 Alle Personen
Abfrage Anzahl der Kunden, Ergebnis siehe Abbildung 8.40.
- Es wird die Anzahl der Kunden mit Hilfe der SQL-Funktion count() ermittelt.
- Das Ergebnisfeld, das die berechnete Anzahl beinhaltet, bekommt den (frei gewählten) Namen count_ku_id.
select count(ku_id) as count_ku_id from kunde

Abbildung 8.40 Anzahl der Kunden
Abfrage Alle Kunden mit allen Projekten, Ergebnis siehe Abbildung 8.41.
- Es wird für jedes Projekt ein Datensatz ausgegeben.
- In jedem Datensatz stehen die Daten des Projekts und des betreffenden Kunden.
- Die Anzeige ist nach Name, Ort und Bezeichnung sortiert.
select * from kunde, projekt
where ku_id = pr_ku_id
order by ku_name, ku_ort, pr_bezeichnung
- In jedem Datensatz werden Inhalte aus zwei Tabellen angezeigt. Beide Tabellennamen werden hinter from aufgeführt.
- Es werden nur Datensätze zusammengestellt, bei denen die Feldinhalte aus der Bedingung nach where übereinstimmen.

Abbildung 8.41 Alle Kunden mit allen Projekten
Abfrage Alle Personen mit allen Projektzeiten, Ergebnis siehe Abbildung 8.42.
- Es wird für jede eingetragene Arbeitszeit ein Datensatz ausgegeben.
- In jedem Datensatz stehen die Daten der Arbeitszeit, des betreffenden Projekts und des betreffenden Kunden.
- Die Ausgabe ist nach Nachname, Bezeichnung und Datum sortiert.
select * from projekt, projekt_person, person
where projekt.pr_id = projekt_person.pr_id
and projekt_person.pe_id = person.pe_id
order by pe_nachname, pr_bezeichnung, pp_datum
- In jedem Datensatz werden Inhalte aus drei Tabellen angezeigt. Alle drei Tabellennamen werden hinter from aufgeführt.
- Es werden nur Datensätze zusammengestellt, bei denen die Feldinhalte aus den beiden Bedingungen nach where übereinstimmen.
- Die beiden Feldnamen pr_id und pe_id kommen jeweils in zwei Tabellen vor. Daher müssen Sie jeweils den Tabellennamen (mit nachfolgendem Punkt) zusätzlich angeben. Ansonsten wären die Feldnamen in der SQL-Anweisung nicht eindeutig.

Abbildung 8.42 Alle Personen mit allen Projektzeiten
Abfrage Alle Personen mit Zeitsumme, Ergebnis siehe Abbildung 8.43.
- Es wird für jede Person ein Datensatz ausgegeben.
- Es werden alle Personen, denen mindestens eine Arbeitszeit zugeordnet ist, ausgegeben.
- Es wird die Summe der Arbeitszeiten pro Person mithilfe der SQL-Funktion sum() berechnet.
- Die Ausgabe ist nach Nachname sortiert.
select pe_nachname, sum(pp_zeit) as sum_pp_zeit
from person, projekt_person
where person.pe_id = projekt_person.pe_id
group by person.pe_id, pe_nachname
order by pe_nachname
- Der Anweisungsteil sum ... as bewirkt, dass die SQL-Funktion sum() angewendet wird.
- Es werden alle Einträge im Feld pp_zeit aufsummiert, nach denen gruppiert wurde. Die Gruppierung wird mithilfe von group by durchgeführt.
- Es wird nach den Feldern pe_id und pe_nachname der Tabelle person gruppiert, es werden also alle Arbeitszeiten einer Person summiert. Streng genommen hätte es gereicht, nach pe_id zu gruppieren, da dadurch bereits alle Personen voneinander unterschieden werden. Allerdings soll das Feld pe_nachname ausgegeben werden, daher muss es ebenfalls Teil der Gruppierungsfunktion sein.
- Das Ergebnisfeld, das die berechnete Summe beinhaltet, bekommt den (frei gewählten) Namen sum_pp_zeit. Sie sollten die Ausgabe mithilfe von String.Format() runden, zum Beispiel auf eine Nachkommastelle.

Abbildung 8.43 Alle Personen mit Zeitsumme
Abfrage Alle Projekte mit allen Personenzeiten, Ergebnis siehe Abbildung 8.44.
- Es handelt sich um den gleichen Zusammenhang wie in der Abfrage Alle Personen mit allen Projektzeiten.
- Die Ausgabe ist nur anders sortiert, nach Bezeichnung, Nachname und Datum.
select * from projekt, projekt_person, person
where projekt.pr_id = projekt_person.pr_id
and projekt_person.pe_id = person.pe_id
order by pr_bezeichnung, pe_nachname, pp_datum

Abbildung 8.44 Alle Projekte mit allen Personenzeiten
Abfrage Alle Projekte mit Zeitsumme, Ergebnis siehe Abbildung 8.45.
- Es handelt sich um einen ähnlichen Zusammenhang wie in der Abfrage Alle Personen mit Zeitsumme. Auch diese Ausgabe sollte gerundet werden.
- Es wird nach Projekt statt nach Person gruppiert und entsprechend sortiert.
select pr_bezeichnung, sum(pp_zeit) as sum_pp_zeit
from projekt, projekt_person
where projekt.pr_id = projekt_person.pr_id
group by projekt.pr_id, pr_bezeichnung
order by pr_bezeichnung

Abbildung 8.45 Alle Projekte mit Zeitsumme
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



